
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.random.randn(6, 4),
index=list(range(0, 12, 2)),
columns=list(range(0, 8, 2)))
df1
| 0 | 2 | 4 | 6 | |
|---|---|---|---|---|
| 0 | 2.871237 | -1.083014 | -1.475604 | -0.752170 |
| 2 | -2.706205 | 0.329963 | 0.392216 | -2.409230 |
| 4 | -0.468933 | -0.869137 | -0.228810 | 0.244244 |
| 6 | -0.594944 | 0.586175 | 0.777512 | 0.302765 |
| 8 | 1.919059 | -0.033826 | -0.517170 | 0.952174 |
| 10 | 0.516535 | -0.311024 | -0.237281 | 0.986209 |
df1[2] # column labelled 2, like a python dictionary
0 -1.083014
2 0.329963
4 -0.869137
6 0.586175
8 -0.033826
10 -0.311024
Name: 2, dtype: float64
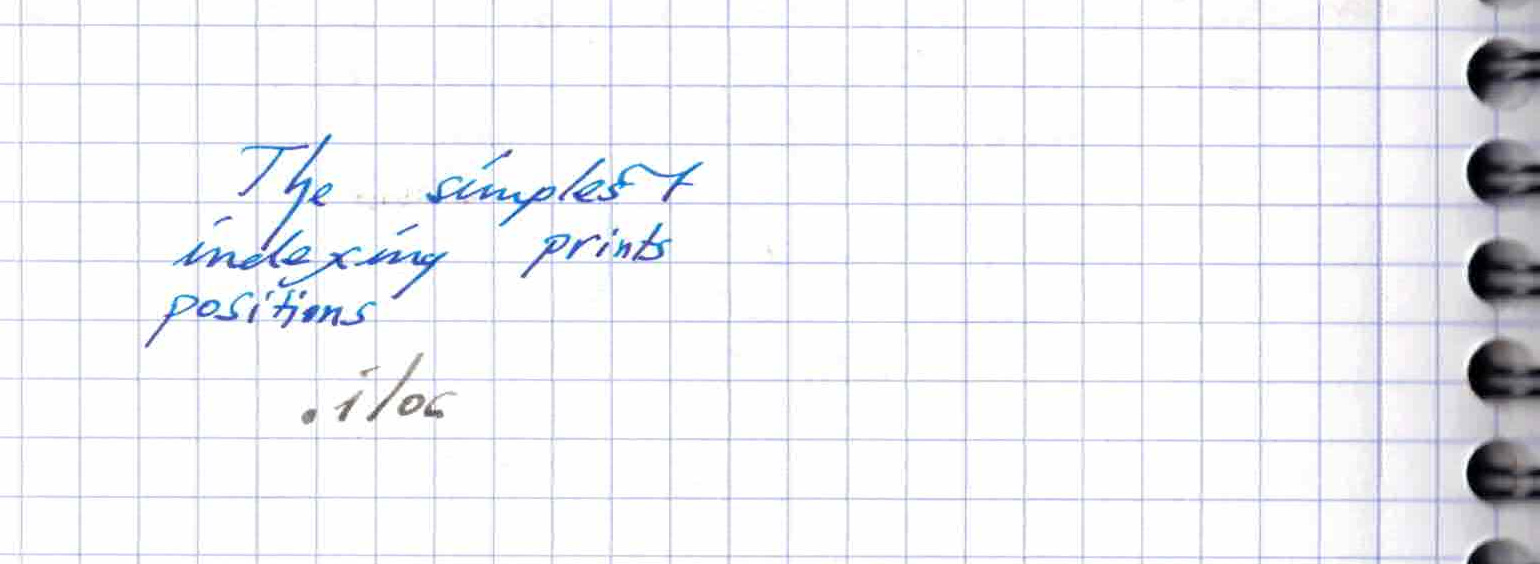
df1.iloc[2] # row in second position of dataframe
0 -0.468933
2 -0.869137
4 -0.228810
6 0.244244
Name: 4, dtype: float64
df1.iloc[2,3] # third entry of the above row
0.24424384065382918
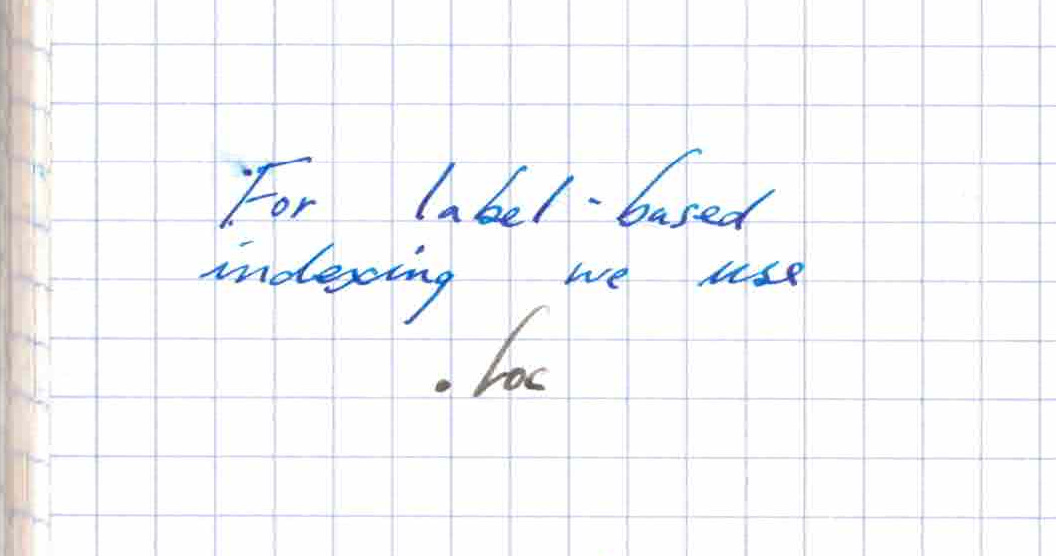
df1.loc[2] # row labelled 2
0 -2.706205
2 0.329963
4 0.392216
6 -2.409230
Name: 2, dtype: float64
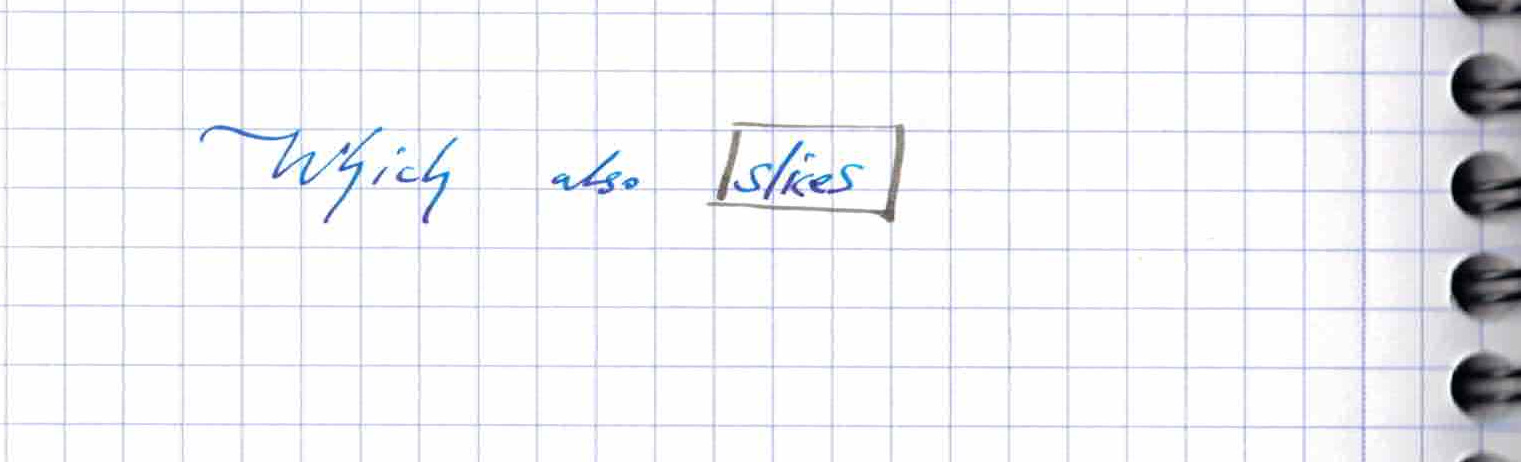
df1.iloc[2:4,2:4]
| 4 | 6 | |
|---|---|---|
| 4 | -0.228810 | 0.244244 |
| 6 | 0.777512 | 0.302765 |
df1.loc[2:4,2:4]
| 2 | 4 | |
|---|---|---|
| 2 | 0.329963 | 0.392216 |
| 4 | -0.869137 | -0.228810 |
 The function takes in the dataframe and returns something that .loc can index on
The function takes in the dataframe and returns something that .loc can index on
df1.loc[lambda df_parameter: df_parameter[2]>0]
| 0 | 2 | 4 | 6 | |
|---|---|---|---|---|
| 2 | -2.706205 | 0.329963 | 0.392216 | -2.409230 |
| 6 | -0.594944 | 0.586175 | 0.777512 | 0.302765 |

df1.loc[df1[2]>0]
| 0 | 2 | 4 | 6 | |
|---|---|---|---|---|
| 2 | -2.706205 | 0.329963 | 0.392216 | -2.409230 |
| 6 | -0.594944 | 0.586175 | 0.777512 | 0.302765 |
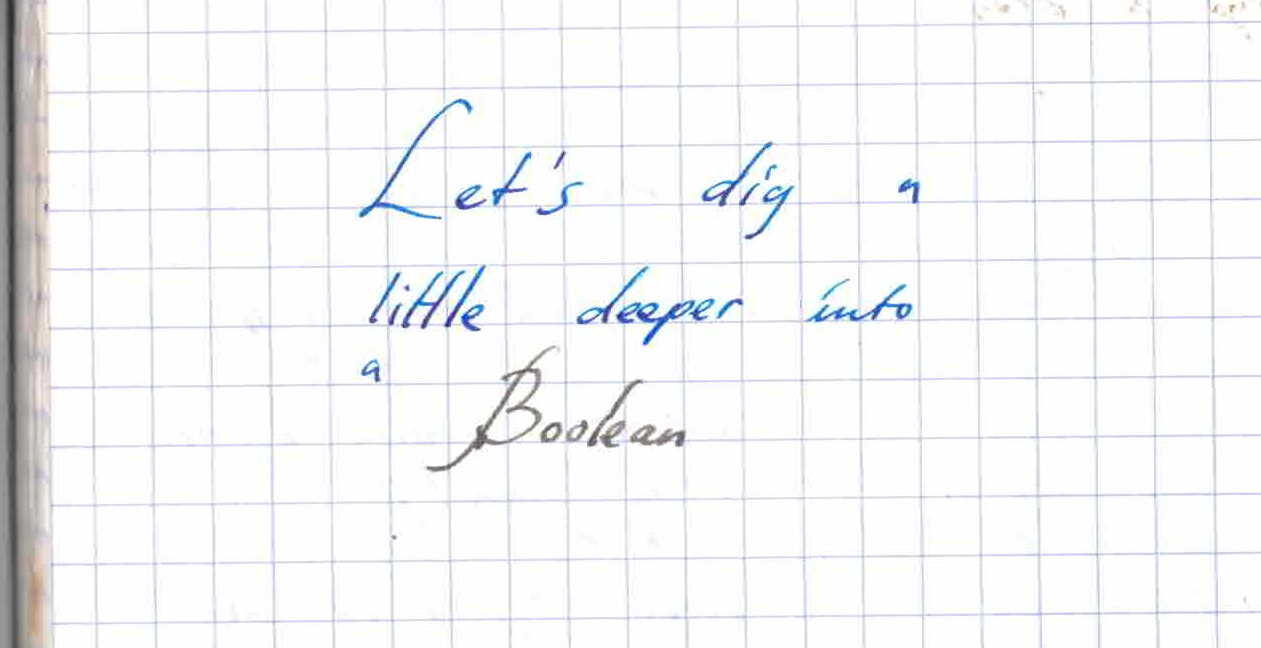
df = pd.DataFrame(
{"AAA": [4, 5, 6, 7], "BBB": [10, 20, 30, 40], "CCC": [100, 50, -30, -50]}
)
df
| AAA | BBB | CCC | |
|---|---|---|---|
| 0 | 4 | 10 | 100 |
| 1 | 5 | 20 | 50 |
| 2 | 6 | 30 | -30 |
| 3 | 7 | 40 | -50 |
df.AAA <= 6
0 True
1 True
2 True
3 False
Name: AAA, dtype: bool
df[(df.AAA <= 6)]
| AAA | BBB | CCC | |
|---|---|---|---|
| 0 | 4 | 10 | 100 |
| 1 | 5 | 20 | 50 |
| 2 | 6 | 30 | -30 |
df[(df.AAA <= 6) & (df.index.isin([0, 2, 4]))]
| AAA | BBB | CCC | |
|---|---|---|---|
| 0 | 4 | 10 | 100 |
| 2 | 6 | 30 | -30 |
df = pd.DataFrame(
{"AAA": [4, 5, 6, 7], "BBB": [10, 20, 30, 40], "CCC": [100, 50, -30, -50]},
index=["foo", "bar", "boo", "kar"],
)
df
| AAA | BBB | CCC | |
|---|---|---|---|
| foo | 4 | 10 | 100 |
| bar | 5 | 20 | 50 |
| boo | 6 | 30 | -30 |
| kar | 7 | 40 | -50 |
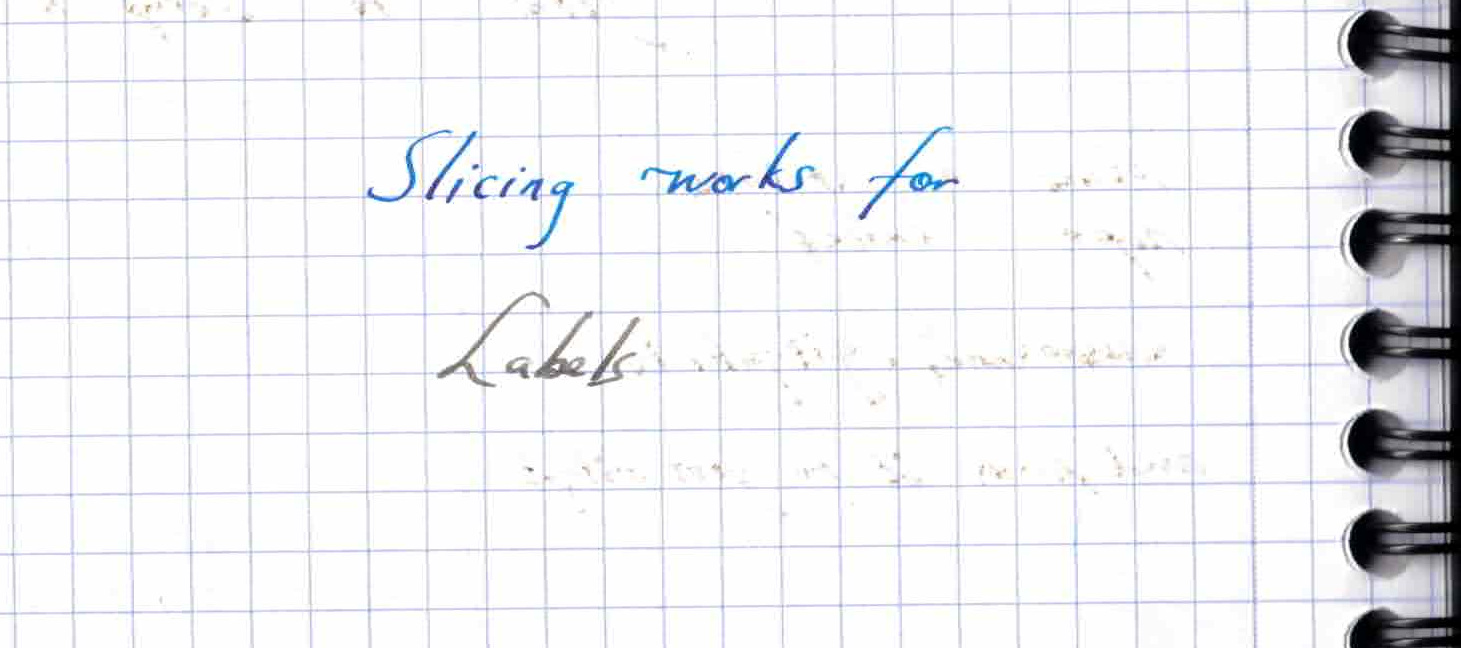
df["bar":"kar"]
| AAA | BBB | CCC | |
|---|---|---|---|
| bar | 5 | 20 | 50 |
| boo | 6 | 30 | -30 |
| kar | 7 | 40 | -50 |
df.loc["bar":"kar"] # Label
| AAA | BBB | CCC | |
|---|---|---|---|
| bar | 5 | 20 | 50 |
| boo | 6 | 30 | -30 |
| kar | 7 | 40 | -50 |
# Generic
df[0:3]
| AAA | BBB | CCC | |
|---|---|---|---|
| foo | 4 | 10 | 100 |
| bar | 5 | 20 | 50 |
| boo | 6 | 30 | -30 |
datadict = {"AAA": [4, 5, 6, 7], "BBB": [10, 20, 30, 40], "CCC": [100, 50, -30, -50]}
datadict
{'AAA': [4, 5, 6, 7], 'BBB': [10, 20, 30, 40], 'CCC': [100, 50, -30, -50]}
df2 = pd.DataFrame(data=datadict, index=[1, 2, 3, 4]) # Note index starts at 1.
df2
| AAA | BBB | CCC | |
|---|---|---|---|
| 1 | 4 | 10 | 100 |
| 2 | 5 | 20 | 50 |
| 3 | 6 | 30 | -30 |
| 4 | 7 | 40 | -50 |
df2.iloc[1:3] # Position-oriented
| AAA | BBB | CCC | |
|---|---|---|---|
| 2 | 5 | 20 | 50 |
| 3 | 6 | 30 | -30 |
df2.loc[1:3] # Label-oriented
| AAA | BBB | CCC | |
|---|---|---|---|
| 1 | 4 | 10 | 100 |
| 2 | 5 | 20 | 50 |
| 3 | 6 | 30 | -30 |
df2[1:3]
| AAA | BBB | CCC | |
|---|---|---|---|
| 2 | 5 | 20 | 50 |
| 3 | 6 | 30 | -30 |

df = pd.DataFrame(
{"AAA": [1, 1, 1, 2, 2, 2, 3, 3], "BBB": [2, 1, 3, 4, 5, 1, 2, 3]}
)
df
| AAA | BBB | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 1 | 1 |
| 2 | 1 | 3 |
| 3 | 2 | 4 |
| 4 | 2 | 5 |
| 5 | 2 | 1 |
| 6 | 3 | 2 |
| 7 | 3 | 3 |

# Method 1 : idxmin() to get the index of the minimums
df.loc[df.groupby("AAA")["BBB"].idxmin()]
| AAA | BBB | |
|---|---|---|
| 1 | 1 | 1 |
| 5 | 2 | 1 |
| 6 | 3 | 2 |
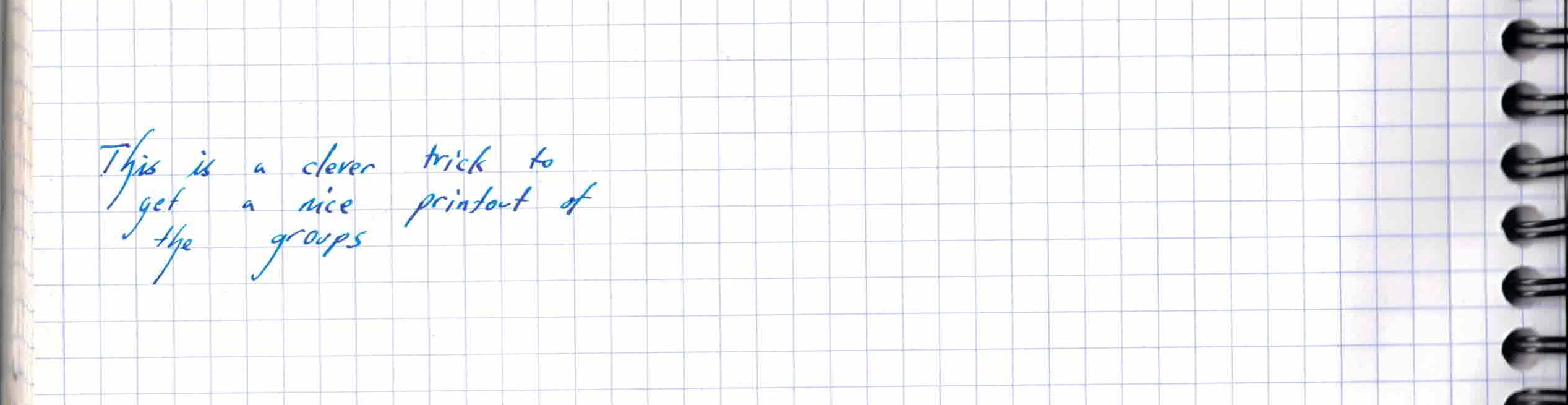
df.groupby("AAA").apply(lambda a: a[:]) # https://stackoverflow.com/a/62803666
| AAA | BBB | ||
|---|---|---|---|
| AAA | |||
| 1 | 0 | 1 | 2 |
| 1 | 1 | 1 | |
| 2 | 1 | 3 | |
| 2 | 3 | 2 | 4 |
| 4 | 2 | 5 | |
| 5 | 2 | 1 | |
| 3 | 6 | 3 | 2 |
| 7 | 3 | 3 |
# Method 2 : sort then take first of each
df.sort_values(by="BBB").groupby("AAA", as_index=False).first()
| AAA | BBB | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 2 | 1 |
| 2 | 3 | 2 |
df.sort_values(by="BBB")
| AAA | BBB | |
|---|---|---|
| 1 | 1 | 1 |
| 5 | 2 | 1 |
| 0 | 1 | 2 |
| 6 | 3 | 2 |
| 2 | 1 | 3 |
| 7 | 3 | 3 |
| 3 | 2 | 4 |
| 4 | 2 | 5 |
df.sort_values(by="BBB").groupby("AAA",as_index=False).apply(lambda a: a[:])
| AAA | BBB | ||
|---|---|---|---|
| 0 | 1 | 1 | 1 |
| 0 | 1 | 2 | |
| 2 | 1 | 3 | |
| 1 | 5 | 2 | 1 |
| 3 | 2 | 4 | |
| 4 | 2 | 5 | |
| 2 | 6 | 3 | 2 |
| 7 | 3 | 3 |
df = pd.DataFrame(
{"AAA": [4, 5, 6, 7], "BBB": [10, 20, 30, 40], "CCC": [100, 50, -30, -50]}
)
df
| AAA | BBB | CCC | |
|---|---|---|---|
| 0 | 4 | 10 | 100 |
| 1 | 5 | 20 | 50 |
| 2 | 6 | 30 | -30 |
| 3 | 7 | 40 | -50 |
df.loc[(df["BBB"] < 15) & (df["CCC"] >= -10)]
| AAA | BBB | CCC | |
|---|---|---|---|
| 0 | 4 | 10 | 100 |
df.loc[(df["BBB"] < 15) | (df["CCC"] >= -10)]
| AAA | BBB | CCC | |
|---|---|---|---|
| 0 | 4 | 10 | 100 |
| 1 | 5 | 20 | 50 |
These examples are taken from the main Pandas website and cookbook:
- https://pandas.pydata.org/docs/user_guide/indexing.html
- https://pandas.pydata.org/docs/user_guide/cookbook.html
Get the jupyter notebook here: Pandas Indexing Notebook